Feedback Cycle Times and Defect Types
Introduction: Feedback as an Economic System
To understand the economics of early defect detection, it is essential to examine the different stages along the development and testing value stream. Each stage provides feedback – but feedback differs dramatically in speed, cost, and reliability.
Feedback is not a single mechanism. It is a layered system of learning cycles, each with its own characteristics:
- how quickly a signal appears,
- which defect types it can reliably detect,
- and how expensive it is to act on that signal.
As a general rule, the further to the right a defect is discovered, the longer the learning cycle and the higher the cost of correction. Understanding these dynamics allows teams to deliberately design where learning should happen – and where it should not.
Connecting Feedback Cycles, Escape Rate, and Resolution Time
Feedback cycle times explain when and where defects can be discovered. Defect Escape Rate and Defect Resolution Time describe what happens when that discovery succeeds or fails.
- Defect Escape Rate (DER) makes visible where feedback is missing. It shows which stages fail to detect the defect types they are intended to catch and therefore allow defects to escape downstream.
- Defect Resolution Time (DRT) makes visible how long the system remains unstable after a defect is discovered. It captures the full recovery time from detection to verified resolution.
Feedback cycles determine the earliest possible moment a defect can be found. Defect Escape Rate shows whether the system actually finds it there. Defect Resolution Time shows the cost of recovering when it does not.
Together, these metrics provide a closed-loop view of quality and flow:
how early the system could learn, whether it actually learned, and how expensive recovery became when it did not.
Feedback Cycles per Stage
Each test stage is best suited for detecting certain defect types. Later stages do not replace earlier ones; they compensate for what cannot be learned earlier. The goal of effective test strategy and shift-left practices is not to eliminate late feedback, but to move repeatable learning upstream.
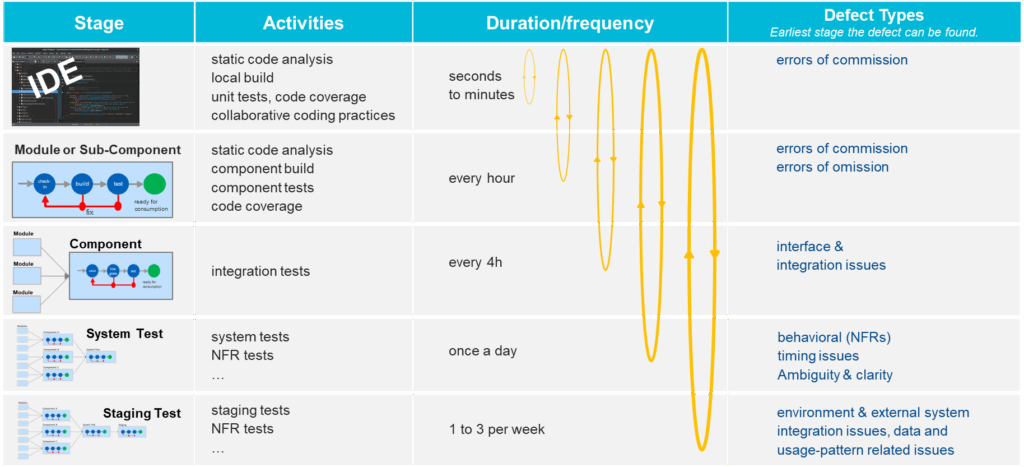
IDE-Level Feedback (Coding Stage)
Best suited to detect: errors of commission
The earliest and fastest feedback occurs directly in the Integrated Development Environment (IDE). Static code analysis, linters, unit tests, and AI-assisted development tools surface issues immediately – often while the developer is still typing.
Collaborative engineering practices1 such as pair programming, peer work, vibe coding, mob programming, and emerging group-AI approaches like MobAI further compress feedback cycles by enabling real-time review, shared context, and rapid validation. While these practices differ in structure and intensity, they all reinforce quality through immediate learning.
Feedback cycles at this stage typically range from seconds to minutes, making them extremely effective for catching defects where code behaves incorrectly despite compiling and running (errors of commission) – such as faulty conditions, incorrect calculations, or misapplied rules. These defects are cheapest to fix here because context is fresh, coordination is minimal, and no downstream dependencies exist yet.
Module or Sub-Component Feedback
Best suited to detect: errors of commission and errors of omission
Once individual changes are integrated into a module or sub-component2, a second layer of feedback becomes active. Component builds, dedicated tests, and coverage checks validate correctness and completeness against defined interfaces and expectations.
Feedback is still relatively fast – often hourly – but it is already more expensive than IDE-level feedback. Time has passed since the code was written, developers are less immersed in context, and diagnostic effort increases.
This stage is particularly effective at uncovering errors of omission: missing logic, incomplete functionality, or unimplemented requirements. Detecting these gaps here prevents them from propagating into later stages, where they become harder to reason about and significantly more expensive to correct.
Component and Multi-Team Integration Stages
Best suited to detect: interface and integration issues
As systems scale, multiple integration stages emerge – often spanning teams, departments, or suppliers. These stages validate whether independently developed components interact correctly and honor shared contracts, data formats, and dependency assumptions.
Feedback cycles lengthen further, commonly measured in hours or days. They become sensitive to environment readiness, integration cadence, and coordination overhead. Defects found here frequently involve mismatched interfaces, incorrect API usage, version conflicts, or incompatible assumptions about about data formats or communication protocols.
Resolution cost rises sharply at this point. Fixing an integration defect typically requires communication across teams, reconstruction of intent, and synchronized changes across components. Context has faded, and the blast radius of changes has grown.
System-Level End-to-End Stages
Best suited to detect: behavioral issues, non-functional requirements, timing problems, ambiguity
At the system level, all components are exercised together to validate functional and non-functional behavior: performance, reliability, security, safety, and overall fitness for use.
Feedback cycles at this stage are inherently long – often measured in days or weeks – because they require full builds, environment provisioning, and coordinated execution. Defects discovered here tend to be emergent: they arise from interactions, timing, load, or hidden dependencies that are not visible in isolation.
By the time system-level defects appear, a significant amount of time has passed since the affected code was written. Fixing them requires deep analysis, cross-team coordination, and extensive revalidation, dramatically increasing cost and delaying flow.
System-level feedback is essential, but recurring discoveries here are strong signals that earlier validation opportunities are missing.
Staging and Production-Like Stages
Best suited to detect: environment-specific and usage-pattern-related issues
Even comprehensive system tests cannot fully replicate real-world conditions. Differences in infrastructure, data, external services, load, and security constraints mean that certain defects only surface in staging or production-like environments.
Feedback cycles here are the slowest and most expensive, often occurring only a few times per week or month. Issues include configuration drift, performance bottlenecks under real load, scaling behavior, and unexpected user patterns.
Defects found this late highlight significant opportunities to shift validation upstream. Each one indicates missing observability, insufficient environment parity, or test gaps that allow expensive learning to happen too late.
Why Defect Types Drift to the Right
Some defect types naturally appear later because they depend on interaction, scale, or realism. Interface issues require multiple components. Non-functional behavior requires load and time. Environment issues require real infrastructure and data.
This does not mean late discovery is acceptable by default—but it explains why not all learning can be shifted left. The goal is to prevent the same classes of defects from repeatedly drifting right by turning late discoveries into earlier validation mechanisms.
Designing Feedback as a System
Feedback cycle time is a design variable. Defect types are signals. Late discoveries represent learning debt.
High-performing value streams are not those that eliminate defects, but those that learn early, cheaply, and repeatedly—and deliberately decide where learning belongs.
References
- Pair programming, formalized in Extreme Programming by Kent Beck (Extreme Programming Explained: Embrace Change, Addison-Wesley), involves two developers working together synchronously on the same task using a driver–navigator model. It provides immediate feedback, continuous review, and strong knowledge sharing.
Peer work (or peer programming) is a broader industry term used across Lean, Agile, and DevOps environments. It does not require synchronous collaboration and includes lightweight practices such as rapid peer reviews, short walkthroughs, collaborative debugging, and feedback-driven design discussions. These patterns are widely described in modern engineering literature, including Accelerate and Software Engineering at Google.
Vibe coding represents an emerging, lighter-weight form of collaborative development in which developers work semi-synchronously in a shared “energy space,” physically or virtually. It emphasizes ambient collaboration, spontaneous support, rapid validation, and fluid knowledge sharing. The practice is discussed in the IT Revolution book Vibe Coding: Building Production-Grade Software With GenAI, Chat, Agents, and Beyond by Gene Kim and Steve Yegge.
Mob programming, introduced and formalized by Woody Zuill (Mob Programming: A Whole Team Approach), involves the entire team working together at the same time on the same problem, sharing one keyboard and screen (or remote equivalent). It creates deep collective alignment, immediate feedback loops, and very high knowledge transfer.
MobAI is an evolution of mob programming in which a team collaborates with one or more AI assistants as part of the collective workflow. The term and practice have been popularized by Joe Justice, whose work with Tesla, Inc. includes applying mob-style collaboration augmented with AI to accelerate engineering flow, reduce handoffs, and drive extremely short learning cycles (source: ABI-Agile, Joe Justice profile, and his public presentations). MobAI combines principles of mob programming with generative AI assistance to enable rapid iteration, exploration, and validation.
Taken together, these practices form a spectrum of collaborative intensity and synchrony:
peer work → vibe coding → pair programming → mob programming → MobAI,
ranging from lightweight, fluid collaboration to fully immersive, whole-team synchronous problem-solving. All share the common goal of shortening feedback cycles, improving quality, increasing shared ownership, and accelerating learning across the value stream. ↩︎ - Terminology such as unit, module, and component may vary across technologies and environments. Adjust the wording to match your system topology. ↩︎
Author: Peter Vollmer – Last Updated on Januar 14, 2026 by Peter Vollmer